We Ran a 3-Source Bug Hunt. Then We Realised Our Validators Were All Claude.
I asked Claude one sentence: “maybe your evaluation was also wrong?” The pipeline had just rolled five P0 severities back to zero. We’d been about to ship the result.
The pipeline was the kind of thing engineering managers ask for when they want “high-confidence” code audits. Three independent passes over the same backend — Claude Opus deep-read, five-agent parallel Sonnet swarm, external Codex review — reconciled by four parallel Sonnet validators. Seventy-two raw findings narrowed to forty-four. Five P0 calls did not survive the validators’ threat-model questions. The validators agreed on every disputed bug — and the architecture diagram of their consensus was clean.
But the question made us notice the thing we’d been carefully not looking at: every validator in our pipeline was the same model family as four of the five hunters. Sonnet rating Sonnet rating Opus. We had built a coalition of related judges and announced their consensus as truth.

What the rollbacks actually looked like
To make this concrete: the swarm’s most aggressive finding was that a legacy chapter-generation worker was “STILL LIVE on the BOOK_GENERATION queue, bypassing the entire new DAG pipeline.” It cited workers/index.ts:340. That line, on inspection, opens a factory function:
// workers/index.ts:337-342 — the factory definition
export function createBookGenerationWorker(): Worker {
const worker = new Worker(
QUEUE_NAMES.BOOK_GENERATION,
async (job) => bookGenerationProcessor.process(job),
...A function defined is not a worker registered. The actual call lives 766 lines later:
// workers/index.ts:1106-1110 — the registration
if (process.env.INCLUDE_BOOK_WORKER === 'true') {
createBookGenerationWorker();
} else {
logger.info('UnifiedWorker: Skipping legacy book-generation worker');
}That part of the audit is honest: default deploy doesn’t set INCLUDE_BOOK_WORKER=true, so the worker is off — the swarm agent had read 337-352 in isolation, never read createAllWorkers(), and conflated “function defined” with “worker running.” Validators caught this and rolled the severity from P1 (active) to P2 (latent behind env flag).
The trouble starts with the other four rollbacks. None were verifiable facts. They were severity judgments — “the SQL-interval-interpolation pattern in the cron health checker is P1 hygiene, not P0 injection.” Defensible. Possibly correct.
The recursion problem has a literature
The research is damning: Wajid Nasser at Viore’s Evaluative Fingerprints: Stable and Systematic Differences in LLM Evaluator Behavior (arxiv:2601.05114, Nasser 2026) ran 3,240 evaluations with nine judges across three independent runs and measured an inter-judge Krippendorff’s α of 0.042 — on two dimensions, judges disagreed more than chance.
The paper’s harshness table is the one we cannot stop thinking about:
| Judge | Mean harshness | 95% CI |
|---|---|---|
| Claude-Opus | −0.429 | [−0.461, −0.399] |
| Claude-Sonnet | −0.340 | [−0.372, −0.307] |
| GPT-5.2 | −0.256 | [−0.290, −0.227] |
| Grok-3 | +0.003 | [−0.033, +0.041] |
| Gemini-3-Pro | +0.262 | [+0.142, +0.370] |
Four Sonnets amplify rather than average out this disposition — Nasser puts it plainly: “averaging judges doesn’t give you ground truth; it gives you a synthetic compromise that matches no judge’s actual values.”
Christo Zietsman generalised the problem in The Specification as Quality Gate (arxiv:2603.25773, Zietsman 2026): AI-reviewing-AI without an executable specification is structurally circular — same training distribution, correlated failures, no external ground truth.
Tae-Eun Song’s Cross-Context Verification (arxiv:2603.21454, Song 2026) is the punchline: “simply repeating verification degrades accuracy: multi-turn review generates false positives faster than it discovers true errors.” Our eleven verification stages were a false-positive accretion engine. The failure, the literature shows, is not in the multi-agent structure itself but in the condition it requires — one our pipeline never checked.
The math actually supports multi-agent — under a condition we violated
Multi-agent verification does work — under one condition. Shreshth Rajan’s CodeX-Verify (arxiv:2511.16708, Rajan 2025) proves via submodularity of mutual information that combining agents catches strictly more bugs than any single one if their pairwise conditional correlation is low. Rajan measured ρ between 0.05 and 0.25 across four specialists and got a 39.7-percentage-point gain. The condition is independence.
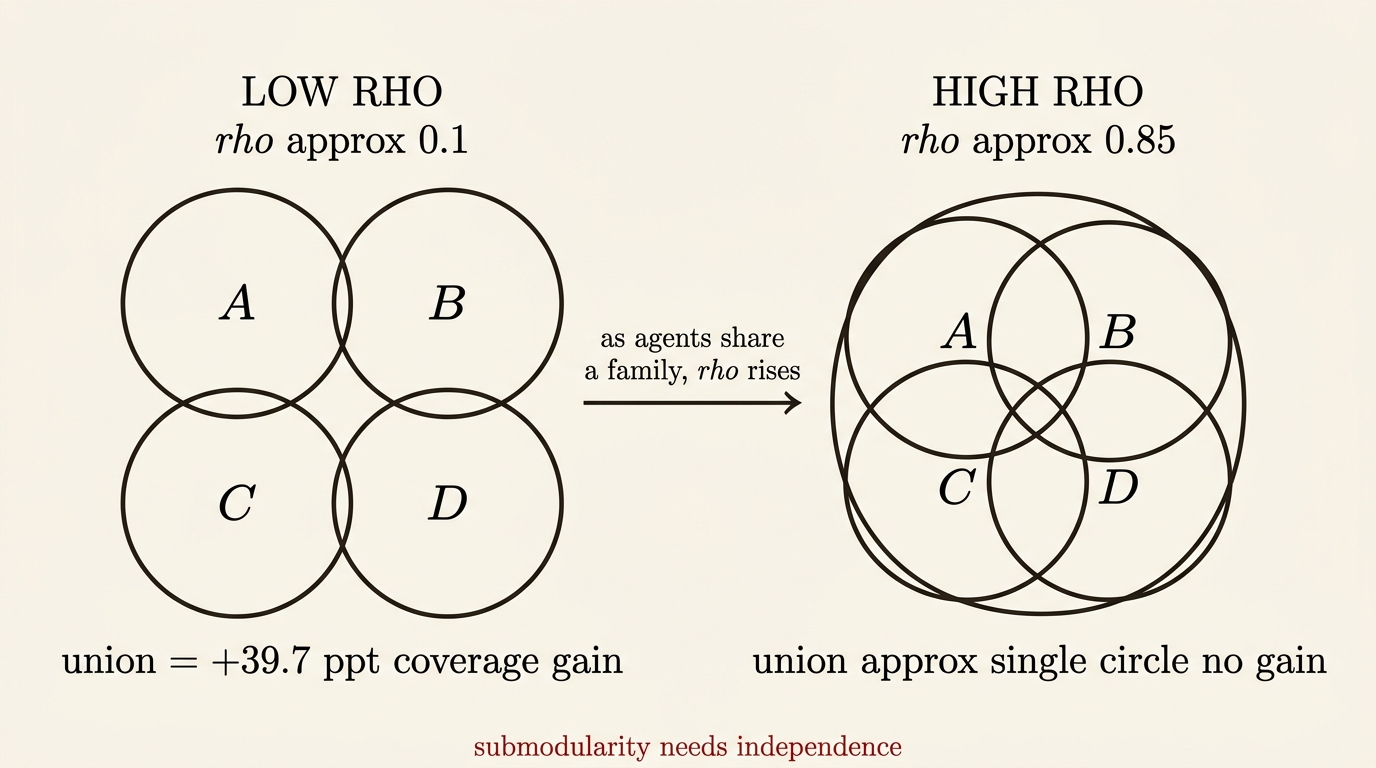
That independence is exactly what Sumanth Karanam et al. (arxiv:2512.21352, Karanam 2025) demonstrated: a three-round vote with GPT-4o, Gemini 2.5 Pro, and Grok 2 found that persona diversity catches a different 88% of bugs per persona — only ~12% overlap. The Inverse-Wisdom Law paper (arxiv:2604.27274, Shehata 2026) calls the homogeneous-swarm failure the Consensus Paradox: agents prioritise internal agreement over external truth.
Self-preference bias intensifies with model capability (arxiv:2504.03846, Chen 2025), and agents that succeed 22% of the time will, when asked, report 77% confidence (arxiv:2602.06948, Kaddour 2026). Confidence is not signal.
What we can and cannot conclude
Once confidence is stripped from the verdict, each finding in the backlog has to earn its standing on different grounds. The audit splits into three classes with very different epistemic standing:
| Class | Example | Confidence | Reason |
|---|---|---|---|
| Verifiable code facts | saveStructuredChapter reads rows[0].node_uuid from a SELECT that aliases kn.uuid — silent no-op at dbOps.ts:485 | High | We can re-read the file in 30 seconds. Judge bias doesn’t apply. |
| Class-of-bug patterns | Ten error-handler call sites all return raw provider errors to the client | Medium | Pattern is observable across all three auditors. Multiple independent paths converged. |
| Severity calls on disputed bugs | ”BUG-01 is P1 not P0 because the SQL-interval payload is internally trusted” | Low | Came from a coalition of harsh same-family judges. Could be right. Could be bias artifact. Cannot tell from inside. |
The “ZERO P0 bugs survive code inspection” headline from our reconciliation report is a Class-3 claim. It does not deserve the confidence the report gave it.
The six things we’d change
Each class in that taxonomy maps to a structural gap in the pipeline, and each gap has a mechanical fix that would have changed the Class-3 verdict before it reached the report. The fix list isn’t surprising once the failure is named. It is, in order of how much it would have helped:
- Heterogeneous-family validators. Not four Sonnets. One Sonnet (harsh), one GPT (different profile), one Gemini (lenient), one Opus arbiter. Disposition diversity by construction.
- Krippendorff’s α calibration gate. Compute α across the deliberators’ independent first-round proposals. Below 0.4, escalate the bug to human review rather than vote on it. Voting on a low-α bug averages incompatible theories of quality.
- Adversarial fabricated-bug injection. Plant five known-fake bugs in the input pile. Measure how many survive validation. Abhinav Agarwal’s Refute-or-Promote (arxiv:2604.19049, Agarwal 2026) formalises this as an adversarial kill mandate: validators are scored on the false-positives they upheld.
- Independent-session ground truth. Run the same audit in three totally separate sessions with no shared context. Per Song 2026, signal lives in cross-session agreement, not in within-session repeated verification.
- Honest confidence intervals on every claim. Not “P1.” Instead “P1 ± 1 (95% CI: [P0, P2]) per N=4 validators with κ=0.3.” Yihan Dai et al.’s Semantic Triangulation (arxiv:2511.12288, Dai 2025) is the closest published method that addresses the no-formal-spec case head-on.
- Wireheading check on validators. After each run, verify the validator actually read the cited file (Read/Grep tool calls in its trace) before upholding severity. A validator that upheld without reading was gaming the measurement, not validating.
What we shipped, what we deferred
Given that list, the only honest criterion for what goes forward is survival across all six failure modes, and most of the disputed backlog does not pass. The trustworthy bugs shipped; the disputed-severity bugs went to a human-review queue, because we have no honest basis to act on a same-family coalition’s word alone. The three class-of-bug PRs from the backlog — error-leak helper, SQL-INTERVAL-interpolation sweep, health-checker fixes — went forward. All three appear in all three audits and survive every validator’s bias. Class-1 facts: re-readable, undisputed, cheap.
The bigger thing this exposed: the codebase needs an executable specification. Without one, every future audit hits Zietsman’s structural-circularity wall — findings will come, some will be correct, none will be robust in the sense that a different judge panel would replicate the verdicts.
Detection fingerprint
Heterogeneous model families is not an optimisation — it is the entry-level condition for the submodularity proof that makes multi-agent review work at all. If you’ve built or are about to build such a pipeline, the test is one prompt: list the model families behind every hunter and every validator. If the list reads “Sonnet, Sonnet, Sonnet, Sonnet, Opus” you have an evaluative coalition, not an audit.
And when you find yourself asking “was your evaluation also wrong?” — that is the moment to search the literature, not to defend the diagram.
Comments
Sign in with GitHub to leave a comment. Threads live on SourceShift/blog-comments — moderated.